聊一点关于 LLM 应用开发
过去的一年,大语言模型 (LLM) 随着 ChatGPT 的横空出世逐渐走进了大众的视野。随着 OpenAI 开放 GPT token 和 LLama 等开源的大模型的出现,越来越多企业和个人开始将 LLM 的智能集成到已有的业务或是个人项目当中 – 其中也包括我自己:在过去一年的大模型应用开发过程中,我尝试过将 LLM Agent 集成到现有创业公司的 2B 业务中,也以开源的形式做了数个面向 C 端用户的 LLM Agent,并且有数千用户下载使用。总的来说,LLM 的到来将会极大地改变现有的软件开发流程和架构,并且衍生出许多新的设计模式和开发生态。趁工作之余,我想把这一年来的一些关于 LLM 开发的零零碎碎的感悟记录一下,希望能够有所帮助。
LLM 应用开发:本质还是软件工程
想起 2018 年,正是深度学习和计算机视觉热火朝天的时候,大学宿舍里总是随处可见李航的 《统计学习方法》还有周志华的西瓜书,那时候相关专业的同学都在努力学习人工智能,并且有很大一部分人的职业发展目标是成为一个算法工程师。传统的软件开发技能似乎和 MLE (Machine Learning Engineer) 的技能交集并不多,于是便有了一群学数学和 Python 的同学和一群坚持着前后端开发为就业导向的同学。在高校里面,这两类人往往井水不犯河水,并且互相瞧不起 – 学软工的同学觉得学 AI 同学工程能力差,学 AI 的同学觉得他们是码农,不懂怎么搞 AI 科研。
但是有趣的是,这种 GAP 在工业界明显被缩小了,企业希望招到工程能力强的 MLE,毕竟绝大多数 AI 是用来服务公司的产品和服务的。而当 LLM 到来的这几年,我能明显地感觉到这种 GAP 正在极速消失 – OpenAI 的招聘官网上写到:我们的工程师做很多的研究,我们的研究员做很多的工程。具体而言,做一个好的 LLM 应用,开发者实际上并不需要关心 LLM 本身,甚至很多情况下不需要关心模型的部署以及资源的调度。反而更重要的是关心如何围绕 LLM,做一个稳定而且智能的软件系统,我们把这类系统称作 Compound AI Systems,一个完整的 LLM 应用除了原有前后端以外,可能还集成了向量数据库,搜索引擎和业务工具链。传统的前后端和过硬的编程以及架构能力,就是激发大模型能力的试金石,而修改模型结构,微调和部署优化的需求会在公司里逐渐降低。
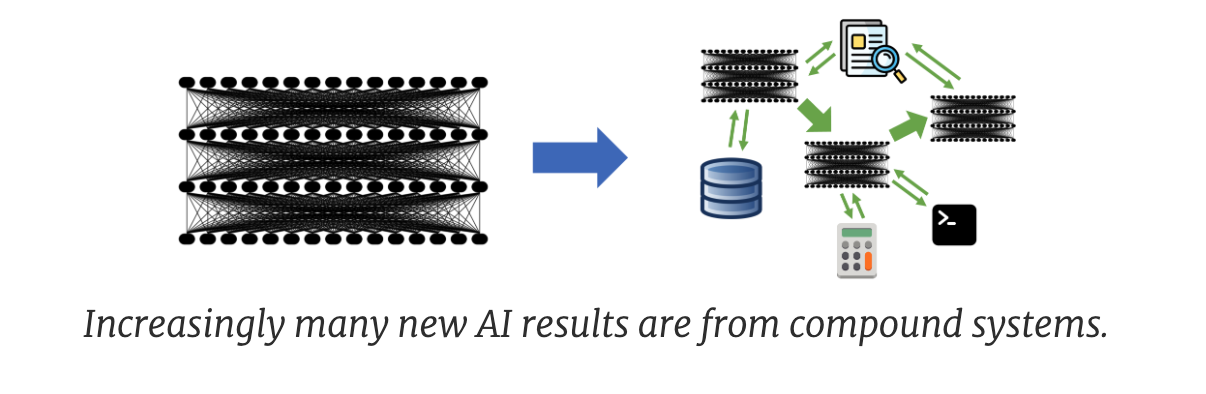
小模型不会离开,而是成为系统的一部分
LLM 是热点,但是不代表传统的小模型和深度学习就会一夜之间消亡。在很多细分的任务里,充分调优的小模型能够取得比大模型更加好的效果,其部署方便,数据隐私性强,推理速度快的特点,公司的业务仍然会选择使用小模型。但是在更为复杂,需要更多智能的任务中,使用大模型无疑是一个好的选择。所以一个成熟的业务不会只使用单纯的小模型或者是大模型,而是一个大小模型相互交互的复杂系统。
举个例子,比如我想做一个能够精准总结网页的应用,直接使用大模型效果不一定好,小模型的总结能力又不够强。但是先让一个关键字提取的小模型处理分析提取杂乱无章网页的关键字,再将其输入大模型进行总结的效果会好很多。同时对于企业来说,比起使用两个不同的 LLM agent 分别做关键词提取和内容总结,还有成本和速度的考量。
所以未来能够看到的很长一段时间里,大模型并不会 dominate 整个 AI 业务圈,而大小模型相互配合的 infra 和应用架构会逐渐成熟。作为学生,如果有时间不能够仅追热点,还是需要从小模型开始,逐渐建立一个完整的 AI 知识体系。
函数调用 Function Calling
另外一个关于 LLM 很深的感悟就是:大模型其实并没有你想像的那么强大。很多人看到 ChatGPT 横空出世的那一霎那,觉得整个世界马上就要变天了。但是当你真正开始创作一个 AI Agent 的时候,你会在 “它真的蠢” 和 “它好聪明” 这两个念头里无限横跳。但是一个上线的业务是无法接受它一会儿蠢和一会儿聪明的,一旦蠢过了一次你可能就会失去用户的信任。
所以一种 LLM agent 的开发思路是:我不让 LLM 去做太多的事情。这个听起来有点反直觉,因为作为一个组合系统中最智能的一部分,大家都会下意识地让手里的大模型负责尽可能多的任务。然而事实是,现在的大模型能力并不足以让它准确地完成所有不同类型地任务,并且你无法保证它每一次都能达到你的预期。所以我们会用微调之后支持函数调用 (Function calling) 的语言模型(如 GPT-4-o, Llama-3-Instruct-function-calling),配合预先实现好的各类功能函数来实现业务逻辑,让 LLM 成为 “使用工具的人”,而不是工具本身。
具体一个例子是,我问 ChatGPT 今天洛杉矶的天气如何,它可能会生成不准确的天气信息。而你写好一个查询天气的函数,并且让它自动调用,那么返回的总是准确无误的信息。函数调用在 LLM agent 的开发中至关重要,一个好的 LLM 应用开发者不仅仅要懂得如何和 LLM 进行对话,更需要判断什么任务需要使用函数完成,什么任务可以交给 LLM,并且在二者的配合中实现业务逻辑。
RAG 和 Search:如何处理大模型幻觉
RAG (Retrieval Augmented Generation) 这个概念在 LLM agent 开发中非常火,但是其原理非常非常简单。举个例子,你问 ChatGPT:
请你解答 UCLA CS111 作业的第五题,题目如下:
....
ChatGPT 不一定会给出很正确的答案,但是你将课程的参考文献作为参考告诉 ChatGPT 后:
请你解答 UCLA CS111 作业的第五题,题目如下:
.....
参考文献:
...
它往往能够得到更好的回答,这个就是一个简单的 RAG:你在与大模型对话的时候,将外部的知识引入了 LLM。 但是衍生出来的问题主要有两个方面:
- 第一是 LLM 的 context window 太小,无法放入足够的外部数据。UCLA CS111 的阅读材料很多,LLM 并不支持将好几本书的内容都放入对话中。
- 放入的数据过多,导致 LLM 的输出变得不稳定出现了幻觉 (hallucination)。可以理解为 LLM 找不着重点了,甚至忘记了你问他什么内容,导致回答变得阿巴阿巴,答非所问。
许多向量数据库 (vector database) 为大模型 RAG 提供了良好的工具支持,它们支持将用户的外部数据,以及个人数据进行编码存储,并且根据这些数据的编码 (embedding) 进行有效的检索,方便开发者将检索到的数据提供给大语言模型。类似的,许多大模型除了使用 RAG 技术以外还会集成搜索功能,将所搜到的外部知识提供给大语言模型,其本质都是相同的,而幻觉问题都普遍地存在于这些方法中。这也是为什么工业界难以大规模地快速普及 LLM:业务场景往往难以接受模型产生的幻觉,没有足够的数据和资源进行大模型地微调,但是又无法抛弃 RAG/search 这类方法带来的效果提升。
所以这也对大模型开发者带来了新的挑战,那就是如何处理输入大语言模型的外部数据。这是一个微妙的平衡,构建一个效果好的 LLM agent 并不像训练巨大的 transformer model,数据越多越好,而是要小心翼翼地评估引入的外部数据的正负反馈,并且在 Compound AI Systems 中,构建良好的数据处理流水线。还是以上述的例子,与其将整本 CS111 的课本放入与大模型地对话中,使用一个向量数据库搜索出最相关的内容作为参考,可以降低占用的 context windows,提供更有效的参考信息。再进一步,对于一些概念性的通用知识,LLM 大概率不需要其特别作为参考数据,将自己的错题还有课程的例题作为参考,反而有更好的效果。
作为一个熟悉 LLM agent 开发的同学,根据具体的业务进行有效的数据处理和筛选,将会是非常重要的一种能力。
Multiple Agent & Human 交互系统
比起大小模型之间的交互,处理复杂的业务逻辑时常需要用到多个智能体进行协同工作。举个例子,在 gpt-researcher 这个项目中为了完成一个端到端的科研任务,LLM 需要扮演 researcher, reviewer, editor, publisher 等不同的角色,每个角色有不同的 system prompt 和使用的 functions/tools,并且不停的交互,直到用户觉得满意了。类似的系统还有很多,我们最近构建了一个端到端的 MLE-Agent, 它能够根据 data scientist 和研究员的需求,进行论文检索,代码编写,测试,报告生成。背后也有 advisor, planner, developer 还有 debugger 进行的多智能体交互。
这类系统主要可以分成两类:
- 一类是固定流程的多智能体交互
- 一类是自由的多智能体交互
像是完成一个科研论文,其流程相对来说比较固定:从做 literature review, 到验证 idea,再到文章撰写,所以可以理解为每一环都由相对独立的智能体负责,并且流程固定,从最初的 agent 到最后 agent,每个 agent 按照顺序执行一遍就可以了。而像是 gpt-pilot 和 OpenDevin 这类编程的 LLM 应用,根据用户的需求和实时反馈,系统需要动态调用不同的 agent 来完成最终的编程任务。这类应用往往需要一个图来管理和调用不同的 agent,这也是 LangChain 社区最近将开发精力从 LLM dev toolkit 转变到 Langgraph 这类项目的一个原因。
同时,为了节约成本和提高生成速度,一个系统中地不同 agent 可能有不同的 LLM backend,还是以完成一个科研论文为例,验证论文 idea 主要依靠搜索的函数调用,和生成文章相比所需的智能较少,可以考虑使用能力较弱的 LLM。具体的实现和选择方式需要根据业务逻辑来决定,而根据业务调整和判断智能体的数量/人机交互/agent 交互方式的能力,对 LLM 应用架构师以及开发者来说也至关重要。
测试流程与安全监管
最后关于 LLM 的开发,不得不提到的就是测试流程和生成式 AI 的安全监管问题 – 这是一个随着 LLM 应用开发的普及不断增长的话题。对于开发者而言,LLM 应用的关键在于如何检测和追踪 LLM 的输入输出,一方面可以帮助自己调整和测试不同版本的 prompt 以达到更好的智能效果,另一方面可以在线上业务出问题的时候,根据自己的 prompt 版本进行有效的版本回滚。有许多初创企业正在探究这类应用,比如 LangFuse 和我们公司 BreezeML,能够预见的是这类测试和追踪平台将会在近几年越来越多。对于企业而言采用第三方的 (如 OpenAI) LLM 服务可能会有用户数据隐私的担忧。如何检测输入 LLM 数据中是否涉及个人身份信息 (PII) ,如何高效地 mask 这类数据但是不影响模型效果成为了一个很重要的考量。
同时从 LLM 的角度出发,如何评估模型的输出没有偏见,没有有害内容,也成为一个影响 LLM 应用普及的重要因素。常见的做法是使用一些人工标注的数据集对大模型进行安全性测试,并且计算一些既定的指标。如 幻觉 (hallucination), 正确性 (correctness), 准确性 (conciseness), 有害性 (toxicity) 等。企业内部往往需要针对自己的业务场景构建这个 LLM 质量评估数据集,这个数据集可能很简单,只包含模型的输入输出,以及各个指标的打分等。