Paper Reading - Serverless for ML
Paper
Title: Cirrus: a Serverless Framework for End-to-end ML Workflows
Author: Joao Carreira, Pedro Fonseca, Alexey Tumanov, Andrew Zhang, Randy Katz
Affiliation: University of California, Berkeley
Publication: SoCC 2019
Background
-
Machine learning (ML) workflows are extremely complex. The typical workflow consists of distinct stages of user interaction, such as preprocessing, training, and tuning, that are repeatedly executed by users but have heterogeneous computational requirements (ML Workflow 十分复杂,包括很多的操作,如数据预处理,模型训练等,后处理等,同时不同任务对于不同的硬件要求不一样).
-
Serverless computing is a compelling model to address the resource management problem (Serverless 将用户提交的任务在云端架构上调度执行,很适合做资源管理,并且为用户提供一个很友好的 interface) .
Motivation
构建一个基于 serverless computing 的分布式机器学习训练框架,能够很好处理 ML training workflow 的资源调度问题,并且充分利用资源,提升系统效率,为用户提供简单易用的接口。
Challenge
端到端 ML Workflow 带来的主要问题
- Over-provisioning: 使用粗粒度虚拟机集群配置 ML Workflow 会因为配置的复杂性, 任务的多样性而常常过度配置所需要的资源,带来资源的浪费。
- Explicit resource management: 将 low-level 的集群虚拟机交给用户去配置会为部署 ML Workflow 带来阻碍。这些配置操作包括 CPU,storage 等资源的 provisioning, configuring, and managing,影响了用户生产力和模型配置的效率。
Serverless + ML Workflow 带来的主要问题
Serverless 和 ML 设计原则上的不一致
Serverless 与 lambda 函数相关的本地资源限制(内存、cpu、存储、网络)相比其他云平台较小,这是 Serverless 的设计基础:通过计算单元的细粒度能够实现系统的可扩展性和灵活性,并且避免资源浪费。然而对于 Deep learning (ML) 任务来说,现有的 ML system 通常会占用一大块的系统资源(如 Spark 会把所有的训练数据加载进内存),这与 serveless 细粒度管理资源的方式有冲突。
具体来说分成一下几个方面:
-
Small local memory and storage. Lambda 函数通常设计的具有很小的内存和存储,比如 AWS Lambda 函数最多只能访问到 3GB RAM 和 512MB 本地存储,这就导致很多 ML 任务在 AWS Lambda 上面运行不现实(比如 TensorFlow 或者是 Spark 这种设计之初就没对 resource 设置限制的平台任务)。
-
Low bandwidth and lack of P2P communication. 和一般的虚拟机相比, Lambda 函数能够占用的带宽是很小的。还是以 AWS Lambda 举例,最大的配置带宽为 60MB/s, 这种配置甚至比中等型号的 VM 还小。而且不支持 P2P 通信,导致很多分布式算法不能用,如 Ring AllReduce。
-
Short-lived and unpredictable launch times. Lambda 函数持续时间不长,并且启动和关闭时间是不固定的,这就导致一个问题:ML 训练是长时间的,那么就需要 ML Workflow 能够容忍 worker 的频繁加入或者是离开中断。像 MPI (used, for instance, by Horovod and Multiverso)这类运行时是无法与这样的系统结果兼容的。
-
Lack of fast shared storage. Lambda 函数是存储分离的,而且不同的 lambda function之间是无法通信的(如果通信违反了函数式设计),导致对于 ML 任务来说,不同的 worker 需要共享的存储空间来进行训练数据的存放,这对外置的存储来说至少有以下几个要求:低时延,高吞吐,并且支持不同种类 ML Workload,这在目前是不存在的。
Related Work
End-to-End ML Workflow
Dataset preprocessing -> Model training -> Hyperparameter tuning
Serverless
PyWren: 使用了远程存储来保证系统能够适应高强度的数据密集型任务,不过这会导致很多 ML Workflow 中的细粒度操作(比如计算节点中的数据通信)产生巨大的开销(如频繁地访问远程数据库)。
Proposed Content
This work proposes Cirrus, a distributed ML training framework that addresses these challenges by leveraging serverless computing(分布式 serverless 模型训练框架)。
三个主要的 contribution:
-
Cirrus 提供了一个极小的 worker 运行时 (大约比 PyWren 的运行时小 10 倍),这个运行时能够适应不同颗粒度的 lambda 函数,并且能够帮助用户自动选择最合适的云端配置,以达到最省钱或者是最快的预期目标。
-
Cirrus 能够节约大量的内存,存储需求(这是很多 ML 任务的基本需求)。Cirrus 通过远程存储中读取 streaming training minibatches, 并且重新设计分布式训练算法来达到这个目的。
-
Cirrus 使用了 stateless 架构(serverless lambda),这样的话 worker 的开启关闭即使很频繁也能够很好的应对。
系统设计
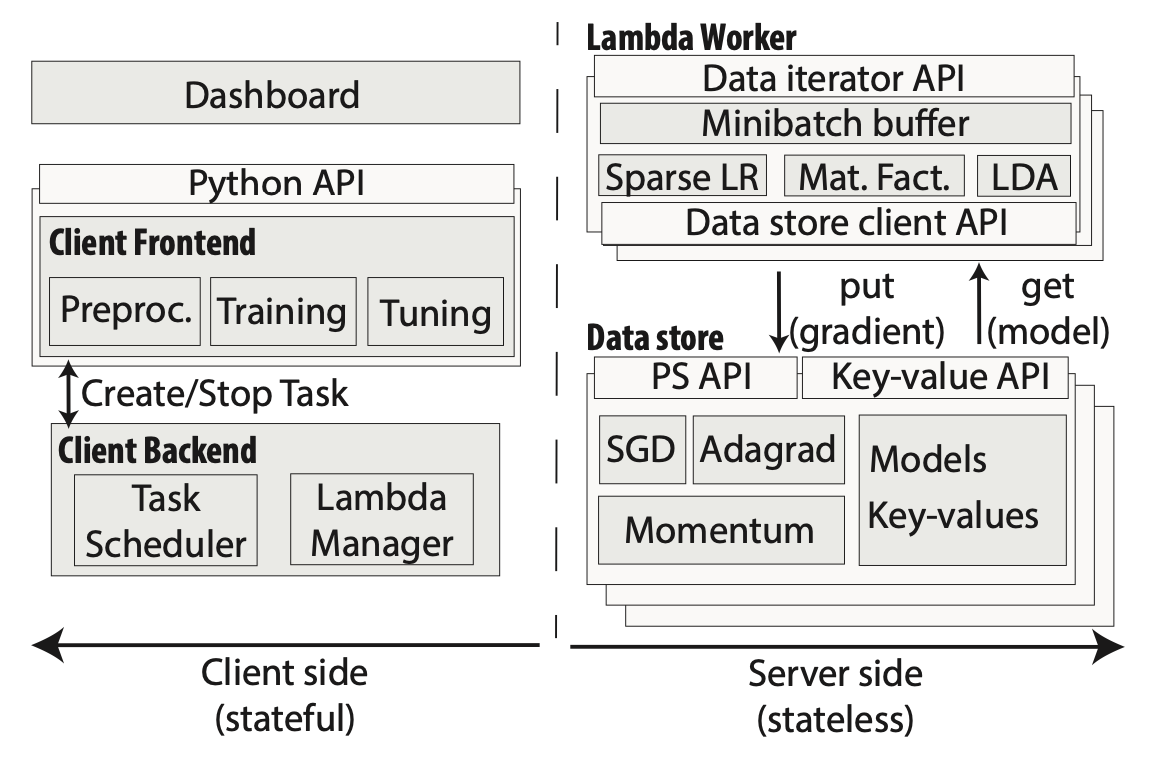
Cirrus system architecture. The system consists of the (stateful) client-side (left) and the (stateless) server-side (right). The client-side contains a user-facing frontend API and supports preprocessing, training, and tuning. The client-side backend manages cloud functions and the allocation of tasks to functions. The server-side consists of the Lambda Worker and the high-performance Data Store components. The lambda worker exports the data iterator API to the client backend and contains efficient implementation for a number of iterative training algorithms. The data store is used for storing gradients, models, and intermediate pre-processing results.