Paper Reading - Active Learning for BERT
Paper
Title: Active Learning for BERT: An Empirical Study
Author: Liat Ein-Dor∗, Alon Halfon∗, Ariel Gera∗, Eyal Shnarch∗, Lena Dankin, Leshem Choshen Marina Danilevsky, Ranit Aharonov, Yoav Katz and Noam Slonim
Affiliation: IBM Research
Publication: EMNLP 2020
Background
- Active Learning (AL) is a ubiquitous paradigm to cope with data scarcity (AL is designed for reducing the data labeling and making full use of training data).
- Recently, pre-trained NLP models, and BERT in particular, are receiving massive attention due to their outstanding performance in various NLP tasks (BERT is popular in NLP tasks).
GAP
- Real world scenarios present a challenge for text classification, since labels are usually expensive and the data is often characterized by class imbalance (data class imbalance and labeling is expensive is a common challenge for text classification).
- The use of AL with deep pre-trained models has so far received little consideration.
- A successful AL approach for a Naive Bayes classifier may not be that effective for a modern deep learning algorithm such as CNN, and vice versa.
Motivation
This paper want to present a large-scale empirical study on active learning techniques for BERT-based classification, addressing a diverse set of AL strategies and datasets.
Related Work
The related work can be divided into:
- Active learning
- Core-Set
- Dropout
- Pre-trained NLP models
- BioBERT
- BERT-CRF
For AL frameworks like Core-Set and Dropout, they focus on image classification with convolutional neural networks (CNNs), cannot handle NLP tasks with BERT or other transformer models.
Some AL frameworks, like
- Zhang et al, Active discriminative text representation learning, 2017 (AAAI)
- Siddhant et al, Deep bayesian active learning for natural language processing: Results of a large-scale empirical study, 2018.
- Shen et al, Deep active learning for named entity recognition, 2017.
They have demonstrated the value of deep active learning for text classification, but not study AL for BERT.
Zhang et al, Albert: A lite bert for self-supervised learning of language representations, 2019. is an exception, but it focuses on a single task, and does not address the effect of small and imbalanced data.
From the perspective of BERT, BioBERT and BERT-CRF only studied a single or two specific tasks, with a small collection of AL strategies.
Proposed Content
This paper is focused on practical scenarios of binary text classification, where the annotation budget is very small, and the data is often skewed. The scenarios include:
- Balanced: A balanced setting, serving as a reference, where the prior of the class of interest is not too small.
- Imbalanced: the more challenging imbalanced setting, where the class prior is ≤ 15% but the paper assumes a way to obtain an unbiased set of positive samples to be used for initial training.
- Imbalanced-practical: the imbalanced-practical setting, which is similar to the imbalanced one, but takes a step further towards a truly practical setup, in which there is no access to an unbiased positive sample.
Datasets
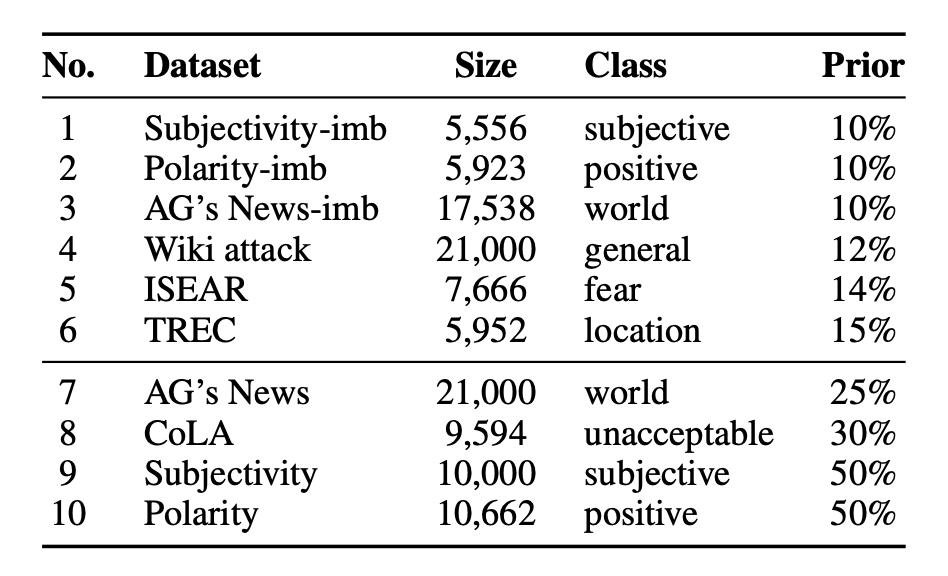
In addition, the authors enriched the imbalanced datasets by creating imbalanced versions of three balanced datasets via sub-sampling the target class instances towards a prior of 10%.
AL Strategy
- Least Confidence (LC)
- Monte Carlo Dropout (Dropout)
- Perceptron Ensemble (PE)
- Expected Gradient Length (EGL)
- Core-Set
- Discriminative Active Learning (DAL)
BERT Training
- Model: BERT-BASE (110M paramaters) was trained for 5 epoch.
- Platform: TensorFlow
Evaluation
The results in this paper demonstrates that AL can boost BERT performance, especially in the most realistic scenario in which the initial set of labeled examples is created using keyword-based queries, resulting in a biased sample of the minority class.
In most datasets, all AL strategies performed better than the Random baseline, but for different strategies, there are differences.
From the system perspective the AL speed is different:

For the learning performance (accuracy) on different datasets and scenarios:
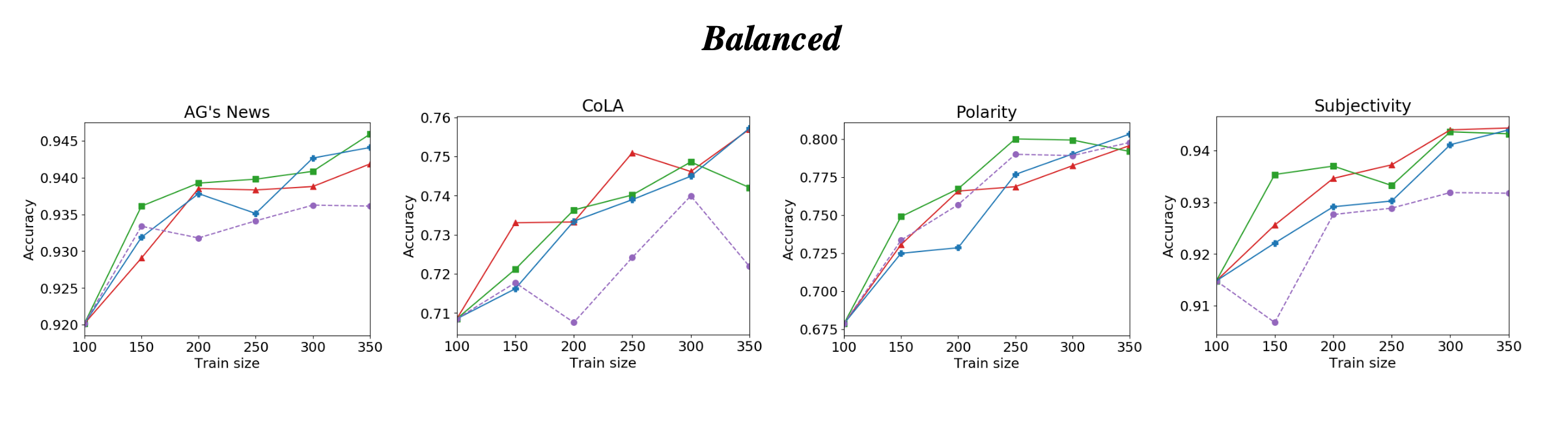
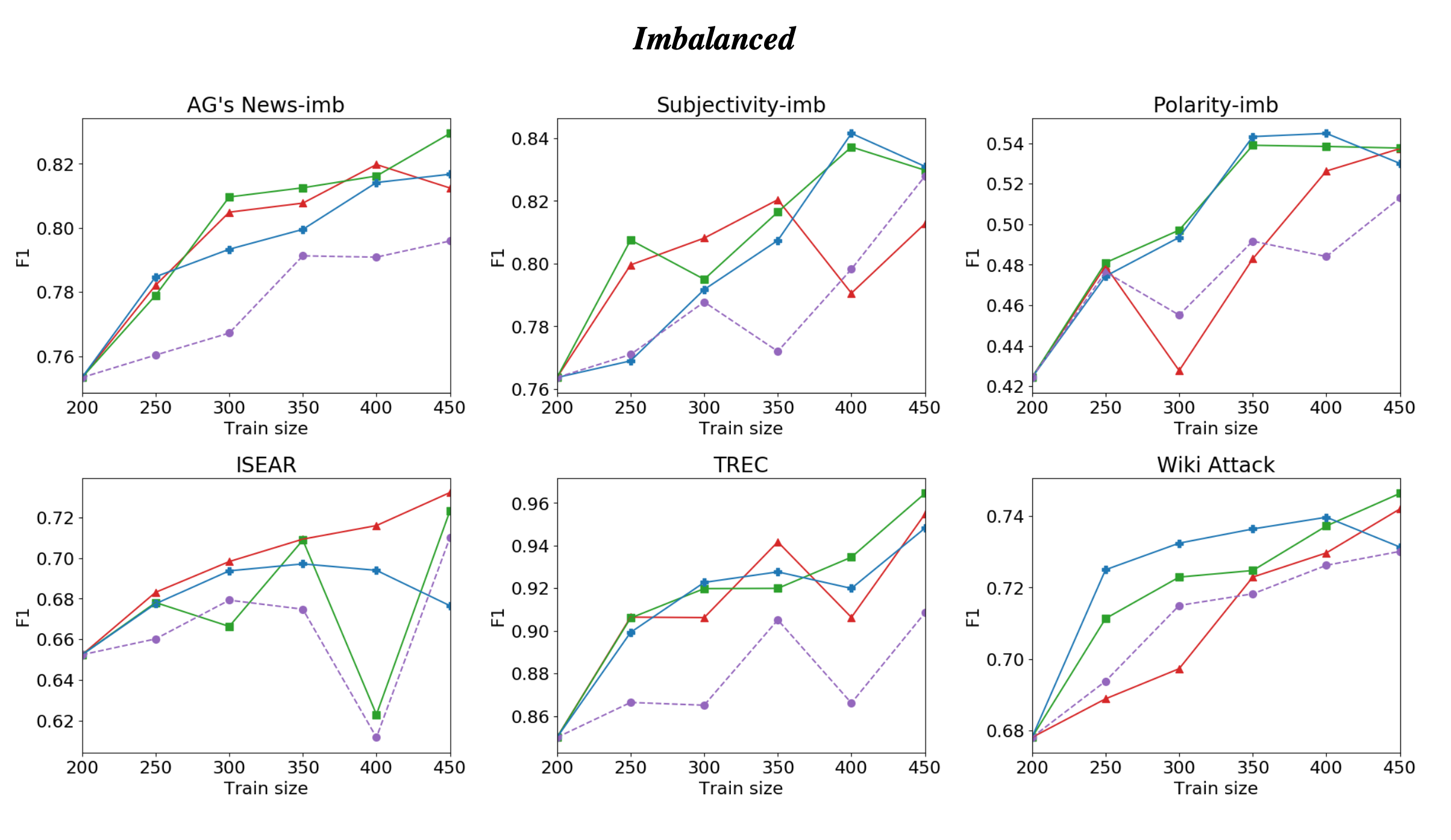
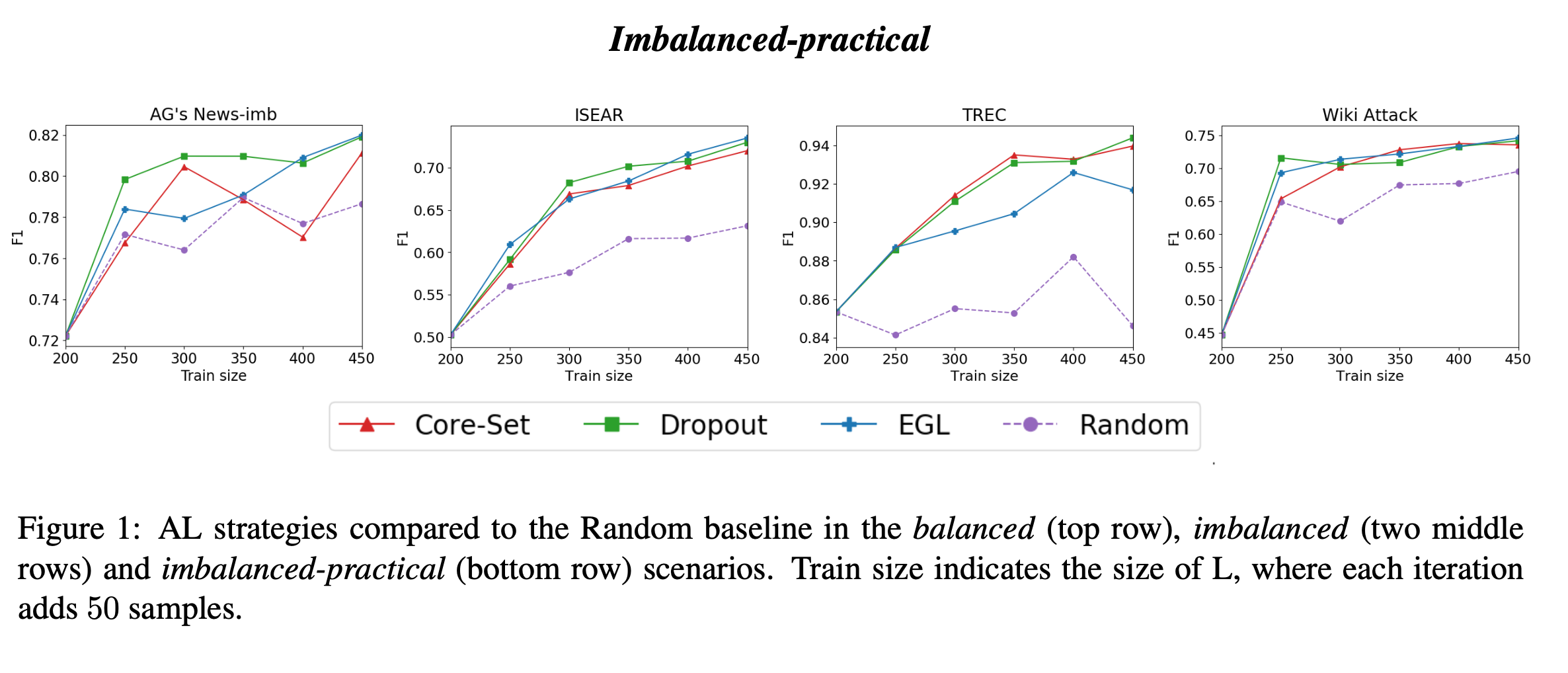
Analysis
The author analysed the results from those perspectives:
- Diversity: choosing a batch of diverse examples is often better than choosing one containing very similar and perhaps redundant examples
- Representativeness: A known issue with AL strategies, especially the uncertainty-based ones, is their tendency to select outlier examples that do not properly represent the overall data distribution, the author exams representativeness of the selected batches using KNN-density measurment.
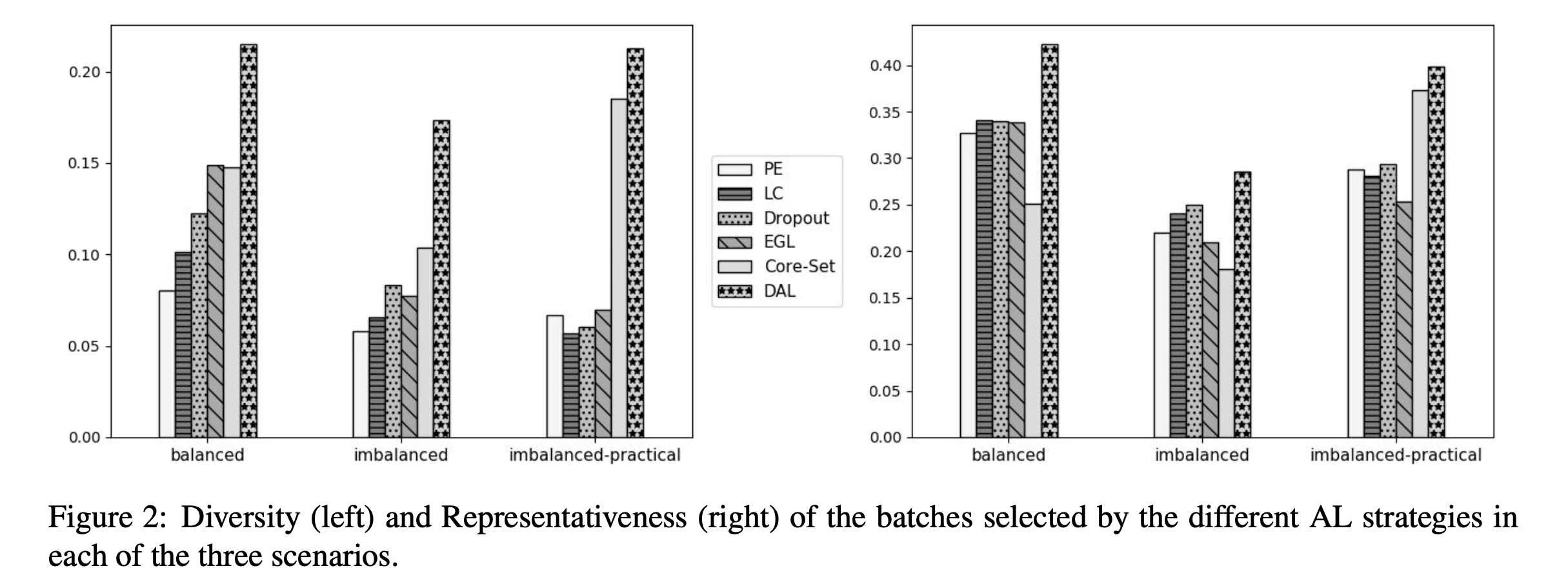
Conclusion
- This paper applies many AL strategies and adopt them for NLP tasks using transformer models.
- This paper does not proposed a new AL methods for BERT and transformer models.
- This paper exam many different learning scenarios and datasets using different AL strategies and gather insights from the analysis of evaluations.